Google Cloud Dataproc is a managed Hadoop MapReduce, Spark, Pig, and Hive service on Google Cloud Platform. I want to get Apache Zeppelin running on Google Cloud and here is what I have gone through.
I see that there is a tutorial on getting Jupyter on Dataproc, so I’d start with that:
Setup a new project
https://cloud.google.com/dataproc/tutorials/jupyter-notebook#set_up_your_project
Create a storage bucket
Prepare initialization actions script
There is actually an initialization actions script for Apache Zeppelin on GitHub, made available by Google. This script automatically sets up Zeppelin to use Spark on the Dataproc cluster.
To use, download the script file from GitHub (raw), and then upload to the storage bucket created in the last step.
gsutil cp zeppelin.sh gs://<bucket-name>/
remember to run
gcloud initfirst
Create a cluster
There are multiple ways to create a cluster. Aside from calling the REST API, one could:
a) create cluster from Create a Cloud Dataproc cluster page
b) or from command line
you can get the command line equivalent from (a) to script this in the future – click ‘command line’ below the ‘Create’ button
It might look something like this
gcloud beta dataproc clusters create cluster-1 \ --zone us-central1-c --master-machine-type n1-standard-2 \ --master-boot-disk-size 500 --num-workers 2 \ --worker-machine-type n1-standard-2 \ --worker-boot-disk-size 500 --image-version 0.2 \ --project <project-name> \ --initialization-actions 'gs://<bucket-name>/zeppelin.sh'
(image-version 0.2 has Spark 1.5.2 – see here for the full list)
Now wait a bit for the cluster – this should take a while since the current script is cloning Apache Zeppelin source code and building it.
to check how things are looking, go to the new cluster on Cloud Platform Console, then on ‘VM instances’ tab, you should see ‘SSH’ next to your master node.
And on SSH, you should see something like this in /usr/lib:
user@cluster-1-m:/usr/lib$ ls drwxr-xr-x 11 root root 4096 Jan 31 22:42 incubator-zeppelin
Connect to Apache Zeppelin
SSH Tunnel
Now to connect to the notebook on a browser, first create an SSH tunnel:
gcloud compute ssh --zone=<cluster-zone> \ --ssh-flag="-D 1080" --ssh-flag="-N" --ssh-flag="-n" <master-node-hostname>
master node hostname should be
cluster-1-mif created as above
This sets up a proxy server at port 1080 on your machine, and will keep running until it is aborted.
Next open a browser to connect through the proxy server, to do that, from a separate terminal window, run:
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome \ --proxy-server="socks5://localhost:1080" \ --host-resolver-rules="MAP * 0.0.0.0 , EXCLUDE localhost" \ --user-data-dir=/tmp/
Type this address in the new browser instance to connect to Zeppelin on your Dataproc cluster:
http://cluster-1-m:8080
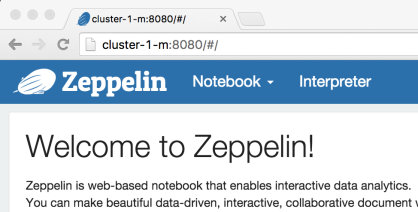
Open port
Alternatively, to open a port with an external address on the firewall (note: this is not advisable unless for testing):
- Open VM Instances, check master, in this case
cluster-1-m - Edit
- in tag, add a tag name
master - in External IP, pick an new name – and then note down the IP
- run this to create the firewall rule (this can be done similarly on Cloud Platform Console) – where 8080 is the default port for Zeppelin
gcloud compute firewall-rules create zeppelin \ --source-ranges 0.0.0.0/0 --allow tcp:8080 \ --target-tags master
(see open-gce-firewall)
Then in any browser, type this for address:
http://‹master-node-external-IP›:8080


